We are excited to share with you a preview of our video course Mapping Urban [...]
7 Comments
We have recently explored Sidewalk Cafés Licensing Data, provided by the NYC Department of [...]
Pandas is one of the most popular tools for data analysis. Here is a pandas [...]
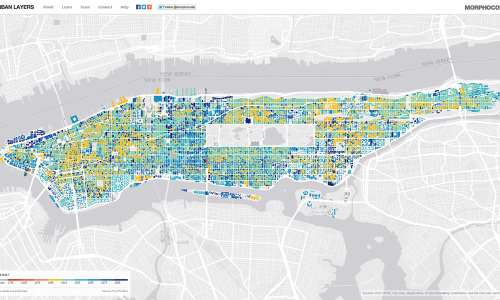
We are happy to announce that Urban Layers is online! Urban Layers is an interactive map created [...]
Username
Password Forgot password?
Keep me signed in until I sign out
First name Last name
Email
Password